Der SQL-Befehl DISTINCT kann Redundanzen eliminieren und gibt die Werte einer definierten Spalte jeweils nur einmal aus. Das DISTINCT Schlüsselwort wird direkt hinter dem Befehl SELECT platziert. Die allgemeine DISTINCT-Syntax lautet:
SELECT DISTINCT Column_name FROM Table;
DISTINCT definiert also welche Spalte auf Redundanzen geprüft werden soll und eliminiert Doppelungen.
Beispiel: Die Tabelle „actor“ beinhaltet einige Schauspieler, die den gleichen Nachnamen haben:
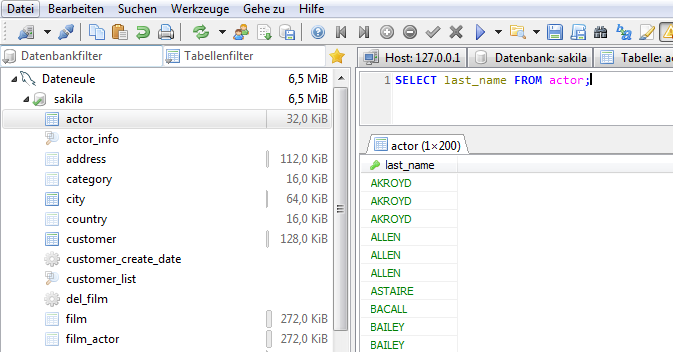
Um die Redundanzen aus der Spalte „last_name“ zu entfernen kann der DISTINCT-Befehl wie folgt eingesetzt werden:
SELECT DISTINCT last_name FROM actor;

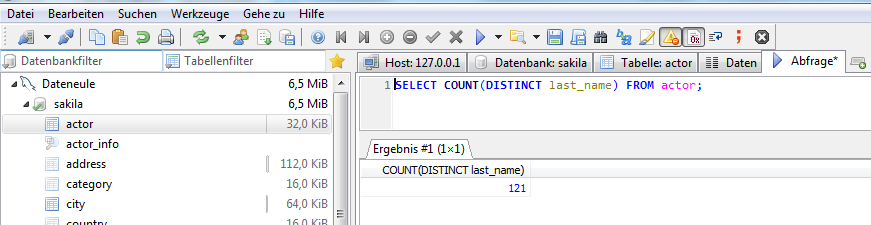
Nun wird jeder Nachname nur einmal angezeigt und die Tabelle gilt als redundanzfrei. Von den 200 Schauspielern gibt es 121 verschiedene Nachnamen und somit 79 Dopplungen.
Wenn zwei oder mehr Spalten in der DISTINCT Klausel angesprochen werden, werden nur die Datensätze ausgegeben, die eine eindeutige Kombination der Spalten beinhalten. Das Schlüsselwort DISTINCT muss nur einmal angegeben werden und nicht für jede Spalte hinzugefügt werden:
SELECT DISTINCT Column_name1, Column_name2 FROM Table;
Beispiel: Wir überprüfen, ob es Doppelungen in der Liste der vollen Namen (Vorname + Nachname) der Schauspieler gibt:
SELECT DISTINCT first_name, last_name FROM actor;
Es werden 199 Datensätze ausgegeben, somit gibt es nur einen Namen, der doppelt ist:

Oft wird DISTINCT genutzt, um neue Dimensionen für ein Data Warehouse aufzubauen, die eine eindeutige Liste an Elementen beinhalten müssen. Aber auch in Kombination mit Aggregationsfunktionen (z.B. COUNT) wird DISTINCT genutzt. Syntax für die COUNT-Funktion:
SELECT COUNT (DISTINCT Column_name ) FROM Table;
Mit Hilfe der COUNT-Funktion wird ausgegeben, wieviele Einträge in der Spalte „last_name“ eindeutig sind:
SELECT COUNT(DISTINCT last_name) FROM actor;

Senior Business Intelligence Consultant
Ihr Steckenpferd: Daten und Mathematik. Seit dem Studium in Controlling, Statistik und KPI’s unterwegs. Expertin in MS Excel und seit mehr als 10 Jahren im Bereich Business Intelligence tätig.

wie macht man die ergebnisse sichtbar ??